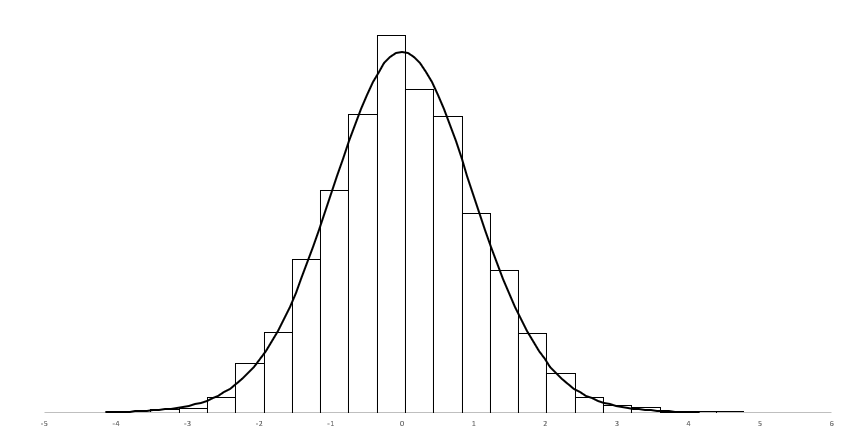
회귀 계수 $\widehat{\beta}_1$은 관찰된 표본에서 나온 값입니다. 회귀 계수를 구해 보면 당연히 표본마다 다를테지만 기대값이 있을 것이고 그 값을 중심으로 흩어져 있을 것입니다. 회귀 계수의 기대값과 분산을 구해 보면 다음과 같습니다(주석 (1)).$$\begin{aligned}E(\widehat{\beta}_1)&=\beta_1\\Var(\widehat{\beta}_1)&=\frac{\sigma^2}{\sum(x_i-\overline{x})^2}\end{aligned}$$그리고 회귀 계수 $\widehat{\beta}_1$는 정규 분포를 따른다고 합니다. 회귀 계수는 $x$가 변할 때 $y$가 변하는 정도인데 $x$는 상수 취급이고 $y$가 정규 분포를 따르니까 그런 것 같기는 합니다.$..